논문: https://arxiv.org/abs/1905.04899
CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features
Regional dropout strategies have been proposed to enhance the performance of convolutional neural network classifiers. They have proved to be effective for guiding the model to attend on less discriminative parts of objects (e.g. leg as opposed to head of
arxiv.org
Title: CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features
Authors: Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, Youngjoon Yoo
Conference: ICCV 2019
DOI: 10.1109/ICCV.2019.00659
Introduction
기존의 regional dropout 기법
입력 이미지의 일정 부분을 무작위로 제거하며, 모델이 객체의 덜 두드러진 부분에 주목하도록 유도하여 네트워크가 더 잘 일반화하고 객체 위치(localization) 능력을 향상한다.
→ 제거된 영역을 대부분 0(검은색)이나 랜덤 노이즈로 채우는 방식을 사용하는데, 이는 학습 이미지에서 유용한 픽셀의 비율을 크게 줄여버린다.
새로운 데이터 증강 기법: CutMix
학습 이미지들 간에 패치를 잘라서 서로 붙여 넣는 방식으로, 해당 패치의 면적 비율에 따라 정답 라벨도 혼합한다.
→ 단순히 픽셀을 지워버리는 대신에 지워진 영역을 다른 이미지의 패치로 대체한다.

장점
- 학습 과정에서 정보가 없는 픽셀이 존재하지 않음
- 모델이 객체의 덜 구분되는 부분에도 주목하게 함 → 일반화 성능 향상
- 패치 형태로 일부만 보이므로 부분적 정보로도 객체를 찾는 localization 능력 강화
- 학습/추론 비용은 기존과 동일
mixup 과의 비교
두 이미지를 픽셀 단위로 선형 보간해서 혼합한다는 점은 유사하다.
하지만 mixup은 이미지가 비현실적으로 변형된다는 단점이 있다.
ResNet-50, Mixup, Cutout, CutMix 실험결과
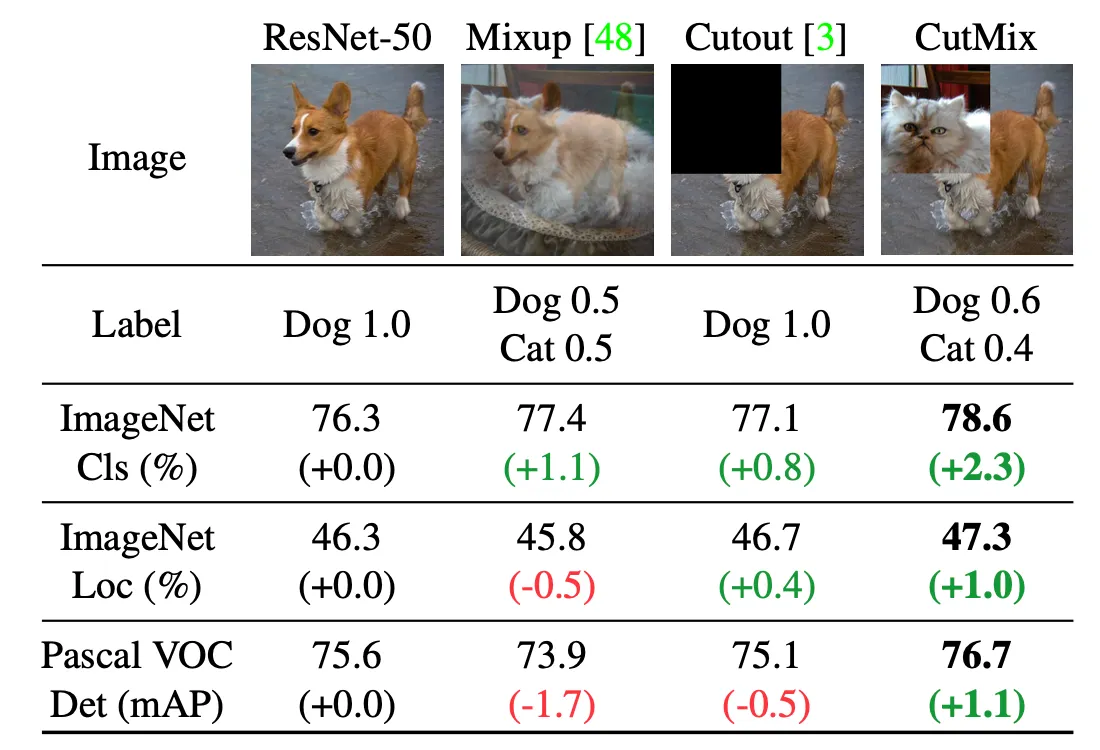
CutMix만 모든 작업에서 성능이 향상됨
CutMix
Algorithm
두 개의 학습 샘플 ($x_A$, $y_A$)와 ($x_B$, $y_B$)를 결합하여 새로운 학습 샘플 ($\tilde{x}$, $\tilde{y}$)를 만드는 것 (x: 이미지, y: 라벨)

$M$: 0 또는 1 사이의 바이너리 마스크, 1이면 $x_A$ 사용 0이면 $x_B$로 교체
$\lambda$: 두 라벨을 섞는 비율 (Mixup과 동일하게 Beta(α, α) 분포에서 샘플링)
마스크 $M$을 만드는 방법
$x_A$에서 잘라낼 영역인 bounding box $B$=($r_x$, $r_y$, $r_w$, $r_h$)를 샘플링
($r_x$: 박스의 x좌표, $r_y$: 박스의 y좌표, $r_w$: 박스의 가로 크기, $r_h$: 박스의 세로 크기)
박스 $B$는 다음과 같이 균등 분포에서 샘플링:
$rx∼Unif(0,W),rw=W\sqrt{1−λ}$
$ry∼Unif(0,H),rh=H\sqrt{1−λ}$
($W$: $x_A$의 가로, $H$: $x_A$의 세로)
따라서 전체 $x_A$에서 bounding box $B$의 비율은 $\frac{r_w r_h}{WH} = 1 - \lambda$
CutMix의 핵심 목적
- 전체 객체의 범위(extent)를 보도록 학습
- 한 이미지에 두 객체가 부분적으로 섞인 상태에서 두 객체를 각각 인식하게 하고, 학습 효율이 증가하게 된다.
CAM 분석 결과 (Saint Bernard vs Poodle)
CAM을 ResNet-50으로 시각화하여 augmentation 효과만 비교

- Cutout: 객체의 덜 중요한 부분에 주목하도록 만들지만, 가린 영역은 정보가 없으므로 비효율적이다.
- Mixup: 모든 픽셀을 사용하지만, 이미지가 비현실적이고 모호하다.
- CutMix: 패치 영역에 실제 다른 객체의 내용이 있고, 두 객체를 명확하게 구분하고 위치도 잘 파악한다.
'AI > Paper Review' 카테고리의 다른 글
| Generative Hints (0) | 2025.12.16 |
|---|---|
| Deep Residual Learning for Image Recognition (0) | 2025.12.12 |
| What is YOLOV5: A Deep look into the internal features of the object detector (0) | 2025.09.23 |
| Distilling the Knowledge in a Neural Network 리뷰 (0) | 2025.09.14 |
| Exploring Better Food Detection via Transfer Learning 리뷰 (0) | 2025.09.07 |


