논문: https://arxiv.org/abs/1503.02531
Distilling the Knowledge in a Neural Network
A very simple way to improve the performance of almost any machine learning algorithm is to train many different models on the same data and then to average their predictions. Unfortunately, making predictions using a whole ensemble of models is cumbersome
arxiv.org
Title: Distilling the Knowledge in a Neural Network
Authors: G. Hinton, O. Vinyals, J. Dean
In NIPS 2014 Deep Learning Workshop
Introduction
본 연구에서는 fine-grained class를 효과적으로 구분할 수 있는 하나 이상의 특화된 모델들(specialist models)로 구성된 앙상블을 활용하고, 이들이 지식을 단일 모델로 증류(distillation)하여 효율적이고 경량화된 모델을 제안하고 있다.
Hard target을 이용할 경우, 각 샘플은 정답 클래스에만 1의 확률을 부여하고 나머지 클래스는 0으로 처리되기 때문에, 세부적인 클래스 간의 관계를 학습하기 어렵다.
ex) [ 0, 1, 0, 0]
Soft target은 정답 이외의 클래스에도 비록 작은 값이지만 확률 분포를 제공하기 때문에, 모델이 오답 클래스 간의 상대적 유사도까지 학습할 수 있어 fine-grained 분류에 더 효과적이다.
ex) [ 0.02, 0.94, 0.01, 0.03]
특수한 경우에는 Logit matching 방법을 사용한다. Logit은 softmax를 적용하기 직전의 값이며, 큰 모델(Teacher)과 작은 모델(Student)의 logit의 차이의 제곱을 최소화하는 방식으로 학습한다.
이렇게 하면 cross-entropy 기반 학습에서 작은 확률 값들이 0에 가까워져 정보가 사라지는 문제를 방지할 수 있다.
Distillation
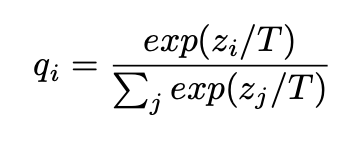
Soft target은 softmax 확률 분포를 말하고, 그 확률을 얻을 때 logit을 Temparature로 나눈 뒤 softmax를 적용한 것이다.
높은 Temparature을 사용할수록 분포가 퍼지고 여러 클래스에 의미 있는 확률이 분배된다.
-가장 기본적인 증류의 형태
큰(Teacher) 모델의 soft target으로 작은(Student) 모델도 학습한다. 학습할 때도 같은 높은 temparature을 사용하고, 학습이 끝난 후 실제 추론 단계에서는 temparature은 1로 사용한다.
Loss 값은 soft target loss와 hard target loss의 가중합을 이용한다.
soft target loss에 더 큰 가중치를 주는 것이 일반적으로 더 좋은 성능을 낸다.

Temparature를 높일수록, gradient 크기가 줄어들어 soft target의 학습 신호가 약해진다.
따라서 최종 Loss의 soft target 부분에 T^2를 곱해줌으로써, soft target의 기여도를 안정적으로 유지한다.

앞서 언급한 것처럼, Temparature가 매우 높아지면 soft target loss는 사실상 logit matching과 같은 효과를 내며, MSE 형태의 학습으로 수렴한다.
즉, student 모델의 logit이 teacher 모델의 logit과 최대한 가까워지도록 학습하는 것과 같다.
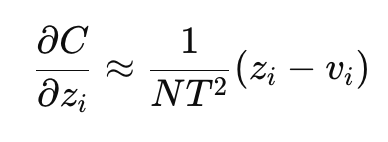
T가 너무 낮으면 hard target과 다를 바 없고, T가 너무 높으면 soft target loss가 사실상 MSE 형태로 수렴하여 오답 클래스들 간의 유용한 정보가 사라지게 된다.
따라서 적절한 크기의 temperature를 선택하는 것이 가장 효과적인 distillation을 수행할 수 있다.
Experiments
1) MNIST
기본 실험
- 대형 모델: hidden layer 2개, 각 층마다 1200개 노드, dropout + weigth-constraint, jittering(2px) → 67 errors
- 소형 모델: hidden layer 2개, 각 층마다 800개 노드 → 146 errors
- 소형 모델: hidden layer 2개, 각 층마다 800개 노드, soft target distillation (T=20) → 74 errors
soft target을 통한 지식 증류가 큰 성능 향상을 제공한다는 것을 알 수 있다.
distilled net의 hidden unit이 300개 이상일 때 T ≥ 8에서는 성능이 비슷하였고, hidden unit이 30개로 줄었을 때 T=2.5~4 범위가 가장 효과적이었다. 즉, Temparature는 모델 크기에 따라 최적값이 다르다.
Transfer set에서 3을 아예 제거하거나, transfer set에서 7과 8로만 테스트한 경우에도 Bias 조정을 통해 보지 못한 클래스(unseen class)도 상당히 정확히 인식 가능하였다.
2) speech recognition
ASR 음향 모델에서 10개의 DNN(Deep Neural Networks) 앙상블이 가진 정보를 단일 모델에 지식 증류(distillation)로 얼마나 잘 전이할 수 있는지 실험하였다.

Baseline 모델: 각 2560개의 노드를 가진 hidden layer 8개, 14,000 개의 클래스를 가지는 출력 softmax layer
→ Frame Accuracy: 58.9%, WER(Word Error Rate): 10.9%
10개의 모델을 앙상블 한 결과: Frame Accuracy: 61.1%, WER(Word Error Rate): 10.7%
하나의 싱글 모델로 지식 증류한 결과: Frame Accuracy: 60.8%, WER(Word Error Rate): 10.7%
(T=1,2,5,10에 대해 실험, hard/soft 손실 가중합의 가중치는 0.5로 설정)
따라서 증류 모델은 앙상블 성능 대부분을 가져오면서도 추론 속도나 연산량은 단일 모델 수준이라서 효율적인 대안임을 확인할 수 있다.
Training ensembles of specialists on very big datasets
대규모 데이터셋에서 모델을 앙상블 방식으로 학습시키는 것은 성능 향상에 매우 효과적이지만, 여러 개의 대형 DNN을 동시에 학습하려면 막대한 연산량과 시간이 필요하다는 한계가 있다.
이를 해결하기 위해 논문에서는 전문가 모델(specialist model) 즉, 특정 클래스들 중에서 서로 혼동되기 쉬운(confusable subset) 그룹에 집중해 학습한 모델들을 도입하고, 이를 효율적으로 앙상블 및 증류(distillation)하는 전략을 사용하였다.
JFT dataset
Google 내부 데이터셋으로 약 1억 장의 라벨링 된 이미지와 15,000개의 클래스를 포함하는 초대형 데이터셋이다.
Baseline 모델은 DNN으로, 비동기 확률적 경사하강법(asynchronous SGD)을 사용해 약 6개월 간 대규모 코어에서 학습되었다.
이때 두 가지 형태의 병렬화(parallelism)가 적용되었다.
1. Data parallelism: 여러 replica 모델이 서로 다른 mini-batch를 학습한 뒤, 평균 gradient를 서로 공유
2. Model parallelism: 하나의 replica 내부에서도 뉴런들을 여러 코어에 분산시켜 병렬 연산
하지만 이렇게 학습한 baseline 모델조차 훈련에 수개월이 소요되었고, 훨씬 더 빠른 방식으로 성능을 개선할 방법이 필요했다.
Specialist Models
클래스 수가 매우 많은 경우에 generalist model과 여러 specialist model을 앙상블 하도록 하였다.
specilaist model은 자신이 학습해야 할 confusable subset과 그 외에 관심 없는 클래스들을 dustbin class로 묶어 학습하였다.
specialist가 다루는 클래스 집합은 generalist model이 예측한 결과를 기반으로 클래스 간 공분산 행렬을 만들어 K-means clustering algorithm을 적용해 confusable subset을 추출한다. 이 subset이 specialist model의 target class가 된다.
specialist model은 처음부터 학습하지 않고, generalist model의 가중치를 초기값으로 가져와 학습을 시작한다. 이렇게 하면 낮은 수준의 특징 추출기를 공유할 수 있고 과적합 위험도 줄일 수 있다. 학습 시에는 절반은 specialist class에서, 절반은 랜덤 클래스에서 데이터를 뽑아 사용한다. 하지만 specialist class는 실제보다 더 자주 등장하게 되므로, 학습이 끝난 뒤에는 dustbin class의 logit을 oversampling 비율만큼 보정해 주어 최종 확률 분포가 왜곡되지 않게 한다.
추론 과정
Step1.
입력 이미지가 들어오면 먼저 generalist model이 전체 클래스에 대한 확률 분포를 출력한다. 이 중에서 가장 높은 클래스 n개를 후보 집합 k로 선택한다.
Step2.
후보 클래스 k와 겹치는 confusable subset을 다루는 specialist model들을 찾아 active set A_k로 설정한다.
generalist model에 대한 확률 분포인 p_q, specialist model에 대한 확률 분포인 p_m을 동시에 고려하여 확률 분포 q를 구한다.
KL divergence 최소화를 통해 q가 generalist model과 specialist model을 모두 반영하도록 한다.
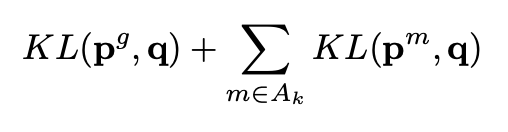
실험 결과
Specialist 모델을 병렬적으로 학습하면 훈련 속도를 크게 단축할 수 있었고, Generalist와 결합했을 때 성능도 꾸준히 향상되었다. 특히 여러 Specialist가 동일한 클래스를 커버할수록 정확도 개선 폭이 커지는 경향이 뚜렷했다. 이는 초대형 데이터셋에서 효율적인 학습 전략으로 Specialist 앙상블이 의미 있음을 보여준다.
Soft Targets as Regularizers

Soft target은 정답만 보는 hard target과 달리 클래스 간 유사성 정보까지 담고 있어 regularizer 역할을 한다. 실험에 따르면 데이터의 3%만 사용해도 soft target을 활용하면 전체 데이터로 학습한 모델과 거의 비슷한 성능을 낼 수 있었다. 또한 Specialist 모델이 confusable subset에만 과적합되지 않고 나머지 클래스들(non-special) 정보도 일정 부분 보존하도록 Generalist가 제공하는 soft target을 함께 학습 신호로 사용하는 것이 효과적임을 보여준다.
Relationship to Mixtures of Experts
Mizutures of Experts
여러 개의 Expert model을 두고, gating network가 각 입력 샘플을 어떤 Expert에게 보낼지 확률적으로 결정한다.
Specialist 모델과 Mixture of Experts는 모두 여러 전문가 모델을 활용한다는 점에서 비슷하다. 그러나 MoE는 Gating network 때문에 학습 병렬화가 어렵고 대규모 데이터셋에 적용하기 힘들다. 반면 Specialist 접근은 Generalist가 먼저 학습된 후 고정된 클래스 subset을 기준으로 Specialist를 독립적으로 학습시키기 때문에 병렬화가 매우 쉽고 효율적이다. 따라서 초대규모 학습 환경에서는 Specialist가 MoE보다 실용적인 대안이다.
Conclusion
지식 증류는 앙상블이나 대형 모델이 가진 지식을 더 작은 모델에 성공적으로 전이가 가능하다. 초대형 네트워크는 앙상블 학습조차 비현실적이다. 대신에 하나의 큰 Generalist를 학습 한 뒤, confusable subset을 다루는 다수의 Specialist를 학습시키면 성능이 크게 향상된다.
Specialist 모델들이 학습한 지식을 다시 Generalist 하나로 재증류할 수 있는지는 아직 보여주지 못했다. 즉, Specialist들의 지식을 다시 하나의 모델로 완전히 통합하는 것은 앞으로 해결해야 할 도전 과제이다.
'AI > Paper Review' 카테고리의 다른 글
| Generative Hints (0) | 2025.12.16 |
|---|---|
| Deep Residual Learning for Image Recognition (0) | 2025.12.12 |
| CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features 정리 (0) | 2025.12.12 |
| What is YOLOV5: A Deep look into the internal features of the object detector (0) | 2025.09.23 |
| Exploring Better Food Detection via Transfer Learning 리뷰 (0) | 2025.09.07 |



