Recall: RNN for Captioning

RNN 기반 Image Captioning은 전체 이미지에 CNN으로 적용해 feature를 추출한 후에 RNN을 적용하는 것이다.
하지만 RNN은 전체 이미지를 한 번만 보기 때문에 정보 손실의 우려가 있다.
Soft Attention for Captioning
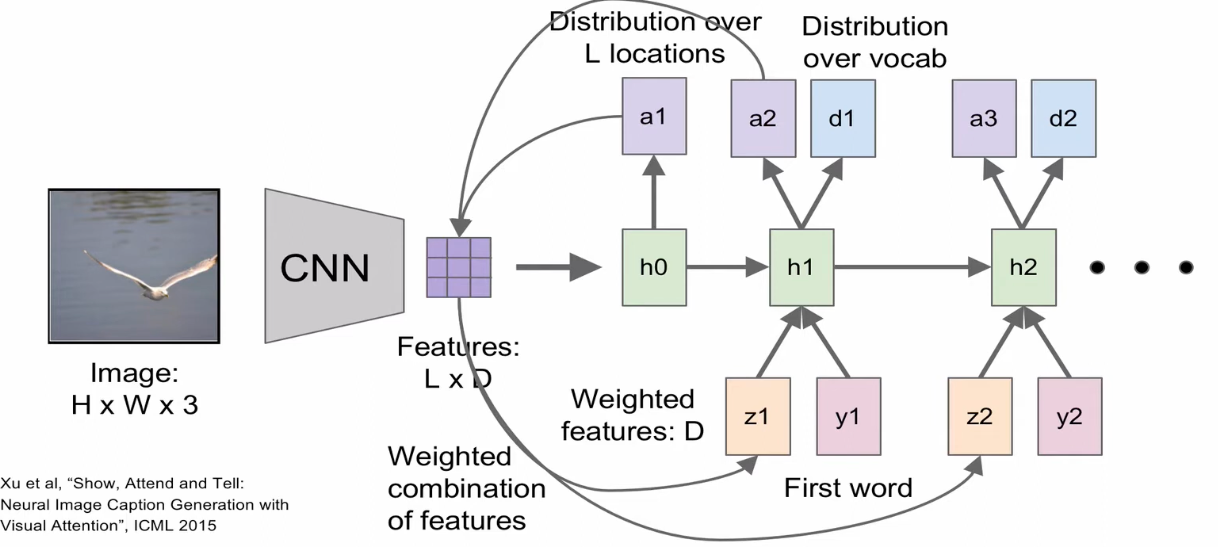
전체 이미지에 CNN을 적용했을 때, 마지막의 FC layer에서 single feature map이 아닌 Conv layer에서 feature grid를 추출한다.
현재 단어를 만들 때 어디를 집중할지를 나타내는 위치에 대한 확률 분포를 계산하여 feature grid에 적용하여 summarize vector를 만들어 다음 상태에 적용한다.
Context vector(summarize vector)

Soft attention에서는 모든 feature와 위치에 대한 확률 분포의 합을 context vector로 사용하고, Hard attention에서는 확률 벡터에서 가장 큰 값(argmax)만을 사용한다. 그렇기 때문에 작은 변화에는 출력값이 변하지 않고 거의 모든 지점에서 dz/dp는 0의 값을 가질 것이므로 end-to-end Backpropagation이 불가능해서 강화학습이 필요하다는 단점이 있다. 하지만 soft attention보다 연산량이 적고 정확도가 다소 높다.

Attention의 한계점은 Fixed grid에 한정되어서 attention을 주는 것이었는데, Arbitrary region에 attention을 주는 모델이 개발되었다.
-DRAW (2015)
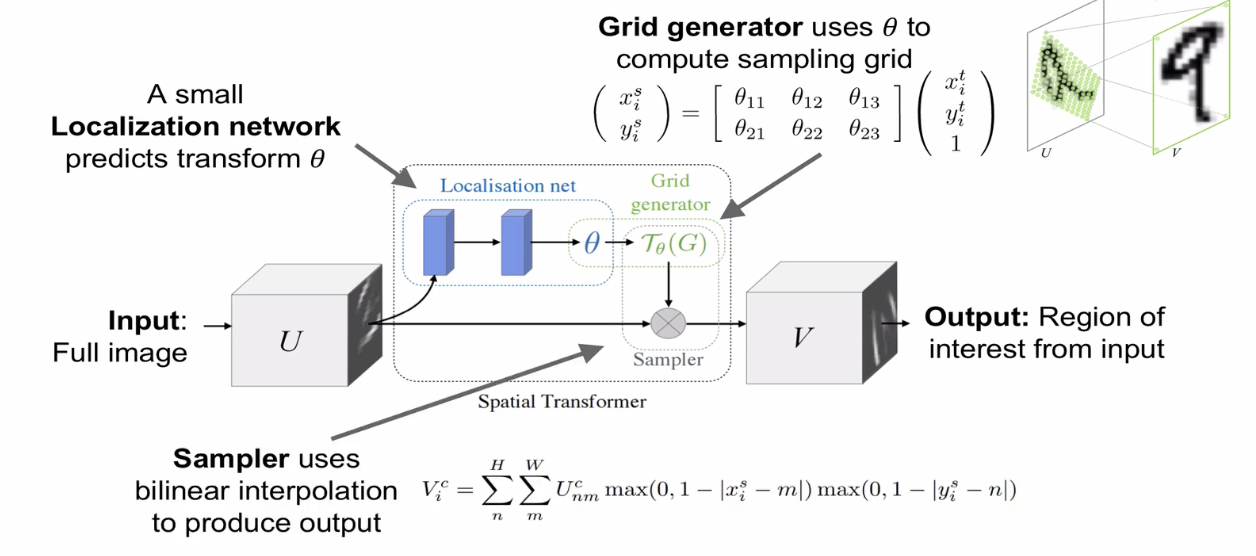
-Spatial Transformer Network (2015)

입력 이미지에서 해당될 object를 localization 하여 box에 대한 좌표를 추출하고 crop, rescaling 한다. 이 과정을 sampling grid로 표현하면 출력 픽셀을 입력 좌표에 매핑하는 식으로 정리할 수 있다.
그리고 최종 이미지는 bilinear interpolation으로 계산하면 되는데, 이 방식은 미분 가능하므로 전체 과정을 end-to-end 학습이 가능하다.
'AI > Stanford Univ. cs231n' 카테고리의 다른 글
| 13-1강 Segmentation (1) | 2025.08.30 |
|---|---|
| 11강 CNNs in Practice (3) | 2025.08.30 |
| 10강 RNN과 LSTM (Recurrent Neural Networks) (7) | 2025.08.24 |
| 9강 Understanding and Visualizing CNN (3) | 2025.08.22 |
| 8강 Spatial Localization and detection, R-CNN (2) | 2025.04.12 |



