Visualize patches that maximally active neurons

AlexNet 구조에서 마지막 풀링 레이어(pool5)의 뉴런 반응을 시각화한 것
pool5는 중간 레벨 이상의 추상적 특징을 잡아내므로, 단순한 edge/texture가 아니라 "개 얼굴", "텍스트", "창문 패턴" 같은 개념적 특징이 시각화된다.
Visualize the filters/kernels (raw weights)

AlexNet의 첫 번째 합성곱 계층(conv1)의 필터들을 시각화한 것
AlexNet의 conv1 필터는 Gabor filter 및 색상 blob 형태를 학습하여 엣지·방향·색상 같은 저수준 특징을 잡아내며,
이런 해석은 주로 첫 번째 계층에서만 직관적으로 가능하다.
Visualizing the representation

AlexNet의 fc7 layer(마지막 분류기 직전의 fully-connected 계층)를 시각화한 것
fc7 layer는 4096차원의 코드(code)로 이미지를 표현한다. 이 벡터는 CNN이 학습한 고차원적이고 추상적인 특징 표현이다.
Occlusion experiments

원본 이미지의 일부분을 회색 블록(square of zeros)으로 가렸을 때, 분류기가 정답 클래스를 맞출 확률이 어떻게 변하는지 시각화한 것
빨간색에 가까울수록 정답 확률이 높은 것이고, 파란색에 가까울수록 정답 확률이 떨어지는 것이다.
ex) 사람의 얼굴을 가렸을 때, Afghan Hound라고 예측할 확률이 매우 높다.
🔗 딥러닝 시각화 프로젝트인 Deep Visualization Toolbox 데모 페이지
Jason Yosinski
Understanding Neural Networks Through Deep Visualization Jason Yosinski, Jeff Clune, Anh Nguyen, Thomas Fuchs, and Hod Lipson Quick links: ICML DL Workshop paper | code | video These images are synthetically generated to maximally activate individual neuro
yosinski.com
주어진 CNN 코드와 비슷한 activation을 내면서, 동시에 자연스러운 이미지를 찾자
Visualizing Activations
뉴런 활성값을 시각화한 것
예를 들어 CNN의 Conv layer를 거치면 feature map이 나오는데, 이것을 feature map이나 이미지로 그려보는 것으로 모델이 입력 이미지에서 어떤 부분에 주목했는지 볼 수 있다.
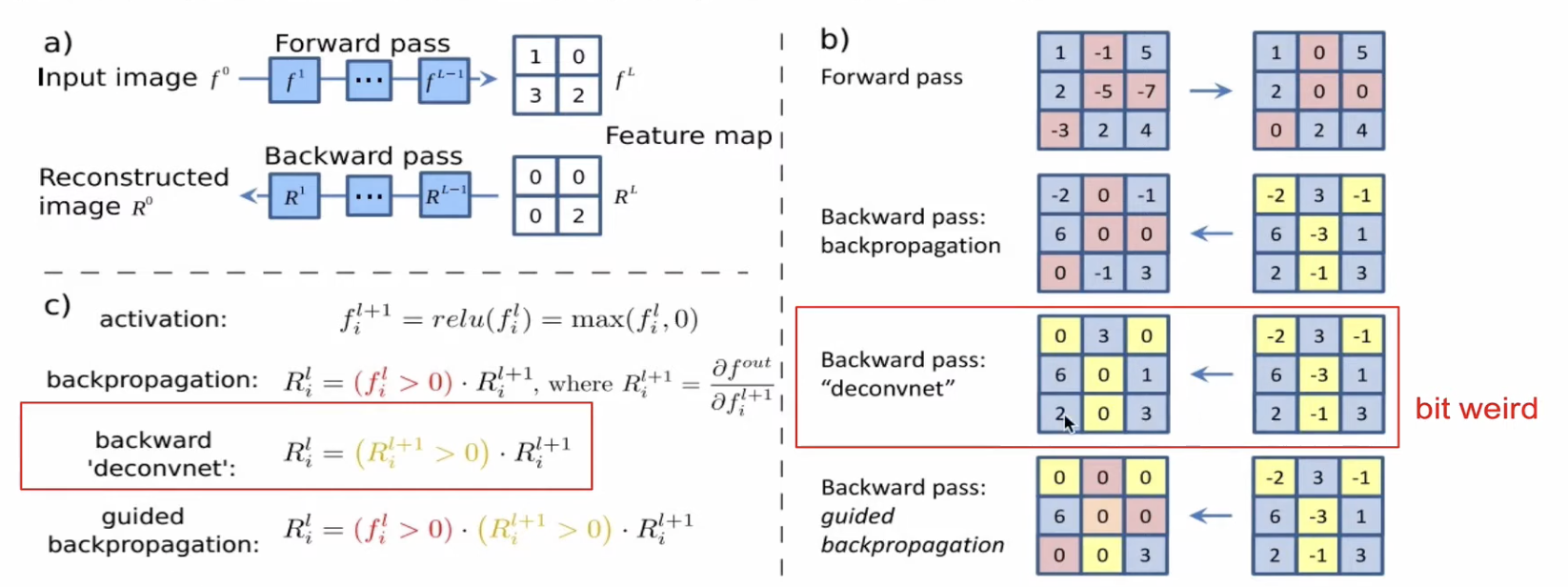
1. Deconvolution-based approach

입력 이미지를 CNN에 적용하면 여러 레이어를 거쳐 feature map을 생성한다. 특정 레이어에서 한 뉴런(채널)에만 관심이 있다고 가정할 때, 해당 뉴런의 gradient를 1로 설정하고 나머지는 0으로 설정한다. gradient를 입력 이미지까지 역전파(backprop)하면 해당 뉴런이 입력에서 어떤 픽셀에 의해 활성화되었는지 추출하게 된다.
(3번에서) 왼쪽 이미지는 기본적인 Backpropagation을 적용한 결과이다. Guided backpropagation을 적용하면 오른쪽 이미지처럼 좀 더 선명하고 중요한 부분이 강조된다.
2. Optimization-based approach
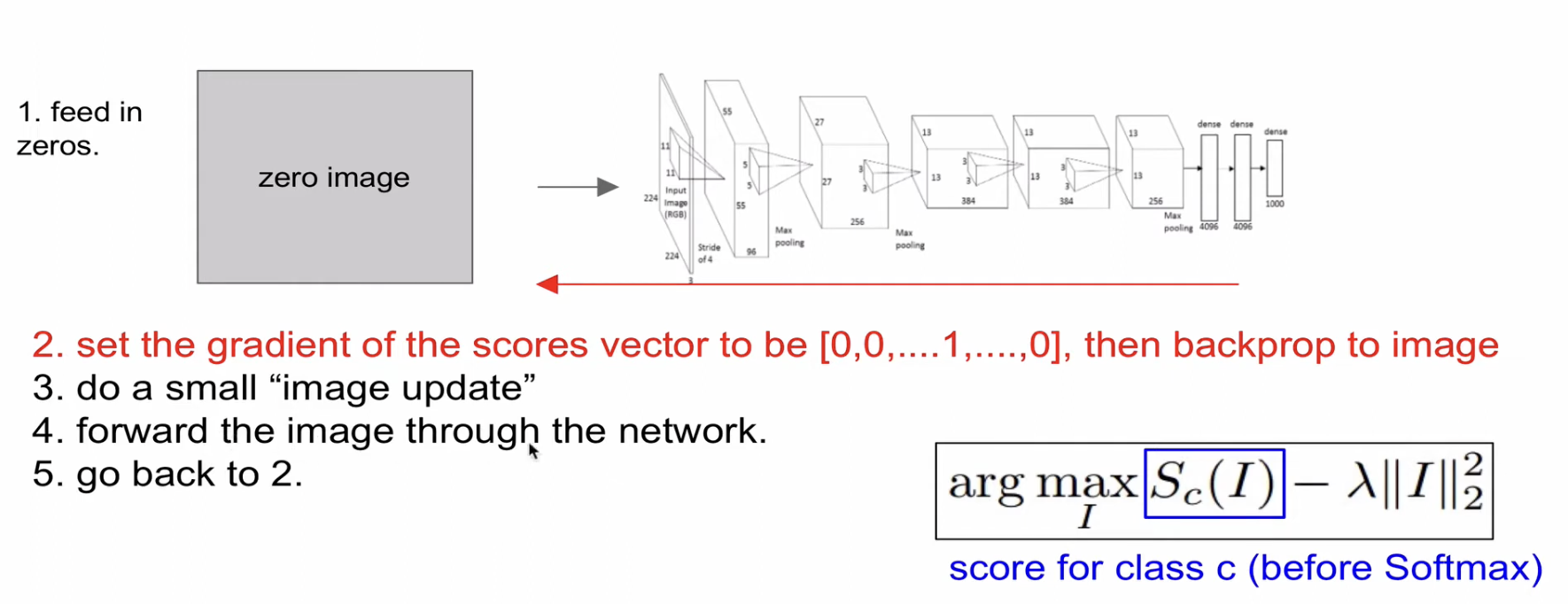
처음에 zero image(혹은 random noise)를 넣고, 관심 있는 클래스에 해당하는 score만 1로 두고 gradient를 계산한다. 그 gradient로 이미지를 조금 업데이트하고 forward pass와 backward pass를 계속 반복해 가며 원하는 이미지를 만들어가는 것이다.
항상 마지막 클래스의 뉴런을 최적화하지 않고, 중간 conv layer의 뉴런을 최적화하여 이미지를 업데이트할 수도 있다.

단순 최적화 시각화에서 생기는 노이즈를 억제해서, 사람이 보기 좋은 패턴으로 만들기 위한 정규화 기법으로 blur 처리를 사용하기도 한다.
visualize the Data gradient

실제 입력 이미지의 data gradient를 구하고 픽셀별로 gradient 크기를 시각화하여 입력에서 중요한 부분 강조하는 방법이다.
즉, “이 이미지에서 모델이 이 클래스로 분류할 때 어떤 픽셀에 의존했는가”를 시각화한 것이다.
CNN의 중간 레이어를 가지고 원본 이미지를 복구(reconstruct, invert)할 수 있을까?
YES
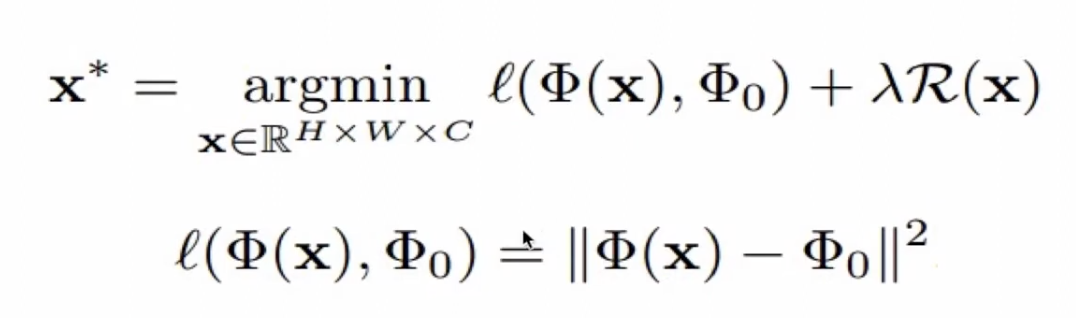
주어진 CNN 코드와 비슷한 activation을 내면서, 동시에 자연스러운 이미지를 찾는 것
우리가 가진 target activation과, 현재 이미지를 CNN에 통과시켜 얻은 activation이 얼마나 비슷한지 최소화하면 네트워크 내부에서 target 코드와 비슷한 표현을 가지게 된다.

DeepDream
구글이 2015년에 발표한 신경망 시각화 기법

입력 이미지를 CNN에 넣고 특정 레이어를 선택하여 해당 activation을 크게 하고 싶다고 설정한다. Backprop으로 입력 이미지에 대한 gradient를 구하고, gradient를 이용해 이미지 픽셀을 gradient ascent로 살짝 업데이트한다. 이 과정을 여러 번 반복하게 되면 이미지 속에서 봤던 패턴이 점점 과장되며 입력 사진이 점점 환각 같은 모습으로 바뀌게 된다.
즉, 실제 사진 속에서 그 뉴런의 반응을 증폭하고 강조하는 것이다.
def objective L2(dst):
dst.diff[:] = dst.data # gradient의 값을 activation으로 설정 (dx=x)
#모든 activation에 대해 boosting이 일어남
def make_step(net, step_size=1.5, end='inception_4c/output', jitter=32, clip=True, objective=objective_L2):
# 이미지를 업데이트할 때 마다 호출
# end: deepdreaming을 할 layer
src = net.blobs['data']
dst = net.blobs[end] # blob의 종류 1. diff field: gradient 정보, data field: raw activation 정보
ox,oy = np.random.randint(-jitter, jitter+1, 2)
src.data[0] = np.roll(np.roll(src.data[0], ox, -1), oy, -2)
net.forward(end=end) # deapdreaming을 원하는 layer까지 forward pass
objective(dst)
net.backward(start=end)
g = src.diff[0] # normalization
src.data[:] += step_size/np.abs(g).mean()*g
src.data[0] = np.roll(np.roll(src.data[0], -ox, -1), -oy, -2) # image update
if clip:
bias = net.transformer.mean['data']
src.data[:] = np.clip(src.data, -bias, 255-bias)
NeuralStyle
한 이미지의 콘텐츠(내용)와 다른 이미지의 스타일(화풍, 질감)을 합쳐서 새로운 이미지를 생성하는 기법

content image를 CNN에 넣어 깊은 레이어 activation을 추출한다. (고수준 구조, 형태 정보)
style image를 CNN에 넣어 얕은 레이어 activation들의 Gram matrix를 추출한다. (저수준 텍스처, 스타일 정보)
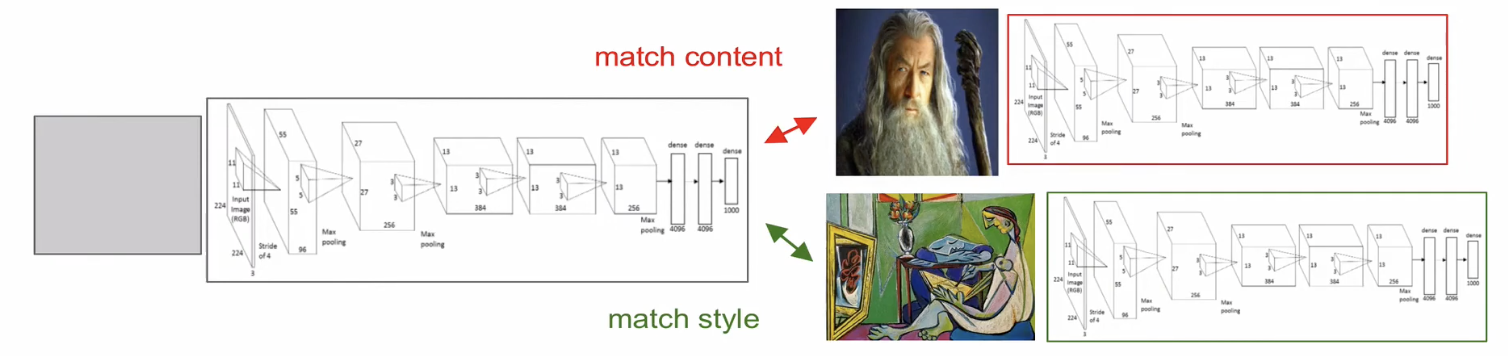
각각 구한 loss에 대한 gradient를 output image 픽셀에 대해 계산하고, output image를 gradient descent로 업데이트하여 점점 content와 style을 동시에 만족하는 결과로 변환한다.
원래는 그 클래스가 아니었던 이미지를 “그 클래스처럼 보이게” 모델을 속일 수 있을까?
YES
즉, ConvNet을 fool(속이는) adversarial attack이 가능하다는 것이다.
신경망이 adversarial perturbation(적대적 작은 교란)에 취약한 가장 큰 이유는 신경망의 선형적 성질 때문이다. 작은 노이즈(선형적 perturbation)도 CNN은 엄청 민감하게 반응한다.
'AI > Stanford Univ. cs231n' 카테고리의 다른 글
| 11강 CNNs in Practice (3) | 2025.08.30 |
|---|---|
| 10강 RNN과 LSTM (Recurrent Neural Networks) (7) | 2025.08.24 |
| 8강 Spatial Localization and detection, R-CNN (2) | 2025.04.12 |
| 7강 Convolutional Neural Networks (0) | 2025.04.05 |
| 6강 Training Neural Networks 2 (0) | 2025.04.04 |



